
By Dan Rosenbloom and John Dinh, Logicworks
Over the years, we’ve created hundreds of scripts to evaluate the status of our AWS environments.
These scripts (we call them “scanners”) run across hundreds of our clients’ environments to detect misconfigurations, and can do things like tell us if AWS CloudWatch is turned off or EBS volumes aren’t encrypted by default. As an AWS Managed Services Provider, Logicworks provides these scanners to all clients as an added layer of protection against configuration errors (or malicious attacks.
Since 2013, we built these scanners as Jenkins jobs, running on dedicated EC2 instances in a central management account. But over the last year and a half, we’ve been converting these Jenkins jobs to AWS Lambda functions.
In this post, we’ll describe why we converted to Lambda, how we did it, and most importantly, how much money we saved (hint: a lot).
Why Lambda?
Our scanners used to run on a Jenkins server, which was on 24×7. Several times an hour it would kick off a script, but most of the time it wasn’t doing a whole lot. We were paying for a lot of compute capacity we weren’t using.
Jenkins jobs have other limitations. It wasn’t easy to get a log of what the scanners were returning. It was difficult to trigger subsequent runs or have “reactions” to the results of the scans. So we started to look for other ways to do it.
AWS Lambda was a natural solution. Lambda is a serverless, consumption-based platform, so we’re not paying for time that Lambdas aren’t running. We also liked the idea of reducing the management overhead of running EC2 instances in our management hub — we already have thousands of instances to manage, so the fewer the better.
How We Converted from Jenkins to Lambda
Lambda lets you run functions in the language of your choice. At the time of this article, Node, Ruby, Java, Go, C#, Powershell and Python are all supported — plus with Firecracker, you could conceivably use any language you want. You can create functions using the console editor or CLI.
Key Terms
Handler: A handler is a function in your code that Lambda can invoke when it executes your code. In the example above, lambda_handler(event,context) is the handler function.
Event: Lambda uses this parameter to pass in event data to the handler. (Usually the Python dict type).
Context: Context is the second parameter in a handler function, provide the run-time information to your handler.
Conversion Process
Most of our scripts were already in Python, so it was just a matter of reformatting them to run as Lambdas. For some of them, there wasn’t any reformatting; it was putting the Python script inside of Lambda handler so it could be triggered on a schedule:
Before (Jenkins Job)
#!/usr/bin/env python from scanners.ec2_events import EventScanner result = EventScanner(account, region)
After (Lambda function)
from scanners.ec2_events import EventScanner def handler(event, _context): return EventScanner(event[‘account’], event[‘region’])
For other functions, we wanted to change them from running through accounts sequentially to running in parallel. We set up CloudWatch event trigger whose function was to trigger one execution per account. It would get a Lambda client of its own inside of that function, pull up a list of accounts to check, then pass the account number to check to subsequent Lambda.
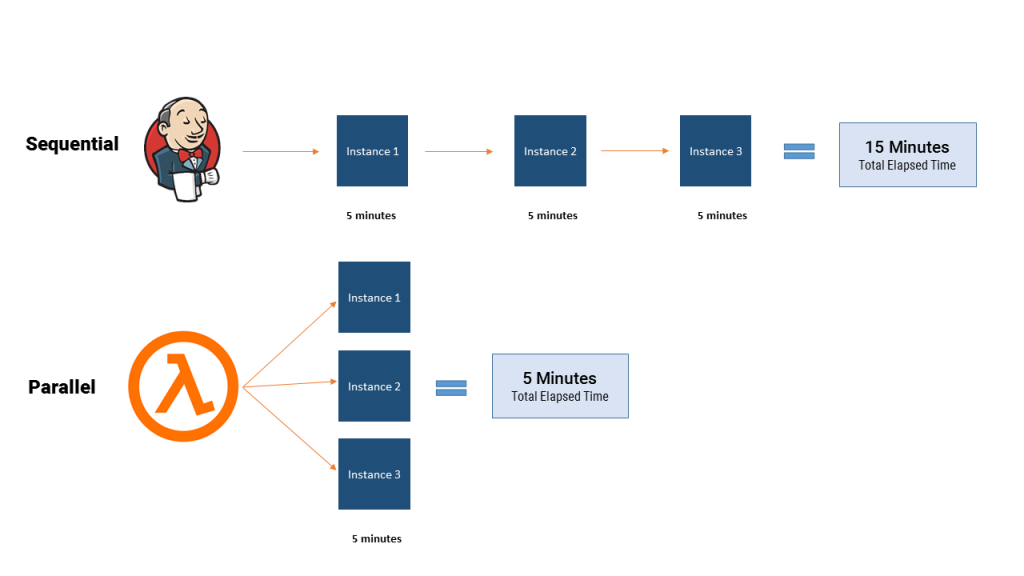
For all scanners, we have at least two Lambda functions: the “runner” Lambda function that initiates the scanner based on a defined configuration, then a separate Lambda function that actually performs the scan. The runner decides at what time it’s appropriate for a given scanner to run, and decides what accounts the scanners should run on.
Orchestrating Multiple Lambda Functions
To build applications of interconnected Lambdas, its much more straightforward to use the Serverless Framework than to just rely on interconnecting Lambdas alone.
The Serverless Framework is an open source framework that supports multiple clouds and plugins. It lets you roll nitty-gritty details into a single process. You don’t have to worry about default IAM role, building dependencies, and if you’re setting up API Gateway it will help with setting up external triggers. It builds and packages all dependencies and connections, making repeated deployments from SDLC processes straightforward. It also gives you a good baseline for how to organize Lambdas and repositories, so that it’s not just a random mixture of CloudFormation templates.
The Serverless Framework has excellent documentation on how to use Serverless with Lambda here.
Summary
If you run scheduled jobs on AWS consider transferring them to Lambda functions. With the solution above, we saved more than 80% on our infrastructure costs, the system was easier to maintain and add to, and we were more confident in the availability of the solution.
Need help managing your AWS environments? Logicworks’ team of 24×7 engineers can help you build, automate, and monitor your AWS cloud. We’re an AWS Premier Consulting Partner and experts in serverless technology. Contact us here.