
Auto scaling has long been one of the major selling points of cloud computing. But like most popularized technology features, it has accumulated its fair share of misconceptions.
These common mistakes tend to get in the way of constructive conversations about cloud architecture, and usually mislead IT leaders into believing auto scaling is simple, quick to set up, and always ensures 100% uptime.
1. Auto scaling is easy
IaaS platforms make auto scaling possible, usually in a way that is much more straightforward than scaling up in a datacenter. But if you visit Amazon Web Services and spin up an instance, you will quickly discover that public cloud does not “come with” auto scaling.
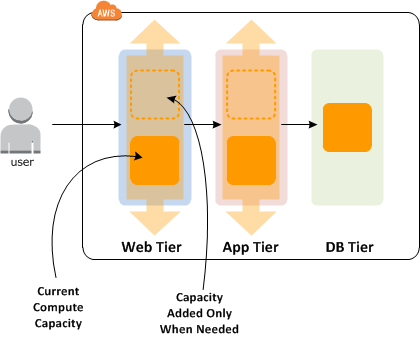
To create an automated, self-healing architecture that replaces failed instances and scales out with little or no human intervention requires a significant time investment upfront. Setting up a load balancing group between multiple Availability Zones (AZs) is more or less straightforward; automatically creating instances with a perfect configuration and minimal standup times requires custom scripts and templates that can take weeks or months to get right, and that does not include the time it takes for engineers to learn how to effectively use AWS’ tools.
At Logicworks, auto scaling usually involves three core components:
- CloudFormation can be used to make a template of the application configuration and resources, modeled as a stack. This template can then be held in a repository, making it reproducible and easily deployable as new instances when needed. CloudFormation allows you to automate things like deploying secure, multi-AZ instances and network infrastructure, and can even download our Puppet scripts and configures the Puppet Master — dozens of small tasks that are very time-consuming if done manually.
- Amazon Machine Images: In the auto scaling process, like in a traditional environment, machine images allow engineers to spin up exact replicas of existing machines (instances). An AMI is used to create a virtual machine within EC2 and serves as the basic unit of deployment. The degree to which the AMI should be customized versus configured on startup with Puppet is a complex topic we discuss briefly below in #4.
- Puppet scripts, and other configuration management tools like Chef, define everything on the servers from a single location, so there is a single source of truth about the state of the entire infrastructure. CloudFormation builds the foundation and installs the Puppet master, and then Puppet attach to the resources the node requires to operate such as Elastic IPs, network interfaces, or additional block storage. A final step is integration between the deploy process and auto scaling, where Puppet scripts automatically update EC2 instances newly added to auto scaling groups (due to instance failure, or scale events).
Maintaining the templates and scripts involved in the auto scaling process is no mean feat. It can take a month for an experienced systems engineer to get comfortable working with JSON in CloudFormation. This is time that small engineering teams usually do not have, which is why many teams never reach the point of true auto scaling and rely instead on some combination of elastic load balancing and manual configuration. Allocating internal or external resources to create template-driven environments can decrease your buildout time by several orders of magnitude.This is why many IT firms devote an entire team of engineers to maintaining automation scripts, often called a DevOps team.
2. Elastic scaling is more common than fixed-size auto scaling
Auto scaling does not necessarily imply load-based scaling. In fact, it could be argued that the most useful aspects of auto scaling focus on high-availability and redundancy, instead of elastic scaling techniques.
The most common purpose for an auto scaling groups is resiliency; instances are put into a fixed-size auto scaling group so that if an instance fails, it is automatically replaced. The simplest use case is an auto scaling group has a min size of 1 and a max of 1.
Furthermore, there’s more ways to scale a cluster than simply looking at CPU load. Auto scaling can also add capacity to work queues, and is especially useful in data analytics projects. A pool of worker servers in an auto scaling group can listen to a queue, execute those actions, and also trigger a spot instance when the queue size reaches a particular number. Like all spot instances, this will only occur if the spot instance price falls below a certain dollar amount. In this way, capacity is only added when it is “nice to have”.
3. Capacity should always match demand
A common misconception about load-based auto scaling is that it is appropriate in every environment.
In fact, some cloud deployments will be more resilient without auto scaling or on a limited basis. This is especially true of small startups that have less than 50 instances, where closely matching capacity and demand has some unexpected consequences.
Let’s say a startup has a traffic peak at 5:00PM. That traffic peak requires twelve EC2 instances, but for the most part they can get by with just two EC2 instances. They decide that in order to save costs and take advantage of their cloud’s auto scaling feature, they will put their instances in an auto scaling group with a maximum size of fifteen and a minimum size of two.
However, one day they get a huge peak of traffic around 10:00AM that is as high as their 5:00PM traffic — but it only lasts for 3 minutes. Whether that traffic is legitimate or not, their website and application goes down.
Why does their website go down if they have auto scaling? There are a number of factors. First, their auto scaling group can only add instances every five minutes by default, and it can take 3-5 minutes for a new instance to be in service. Obviously, their extra capacity will be too late to meet their 10:00AM spike. On top of this, because they do not have enough instances to handle load, it not only triggers the creation of (non-helpful) extra instances, but the existing two servers are so overloaded that the health checks running on those instances start to slow down. When the Elastic Load Balancers see that the health check is not working, it drops the instance. This makes the problem worse and further increases load.
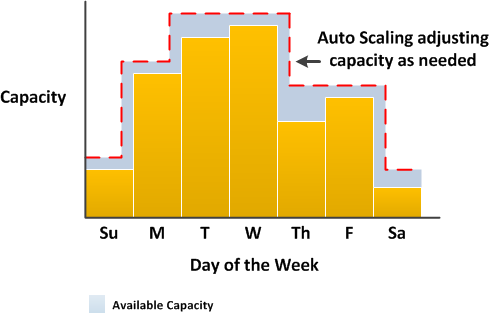
If this happens regularly, it would be wise to reexamine whether scaling down to two instances is a good idea. Even though the startup is saving money by scaling down to match capacity and demand, they are always at the risk of downtime.
In fact, it is generally true that auto scaling is most useful to people who are scaling to hundreds of servers rather than tens of servers. If you let your capacity fall below a certain amount, you are always going to be susceptible to downtime. No matter how the auto scaling group is set up, it still takes at least 5 minutes for an instance to come up; in 5 minutes, you can generate a lot of traffic, and in 10 minutes you can saturate a website. This is why a 90% scale down is almost always too much. In the above example, the startup should instead try to scale the top 20% of their capacity.
4. Perfect base images > lengthy configurations?
It is often very difficult to find the balance between what is baked into the AMI (to create a “Golden Master”) and what is done on launch with a configuration management tool (on top of a “Vanilla AMI”). In reality, how you configure an instance depends on how fast the instance needs to be spun up, how often auto scaling events happen, the average life of an instance, etc.
The advantage of using a configuration management tool and building off of Vanilla AMIs is obvious: if you are running 100+ machines, you update packages in a single place and have a record of every configuration change. We discussed the advantages of configuration management extensively here.
However, in an auto scaling event, you often do not want to have to wait for Puppet or any script to download and install 500MB of packages. In addition, the more tasks that the default installation process must complete, the higher the chance that something will go wrong.
There are also lots of things that can go wrong in a Puppet script. For instance, say that you update OpenSSL to the latest version every time Puppet runs. Even though this happens very rarely, any number of random network issues could cause temporary outages while connecting to the package repository. If the initialization process does not fail elegantly, it could cost a lot of money: the instances keep dying and being recreated, in an hour it might spin up 30 instances and run up a substantial bill, especially if it is running large, production instances.
With time and testing, It is possible to achieve a balance of these two approaches. The ideal would be the ability to start from a stock image created after running Puppet on an instance. The test of a successful deploy process is whether or not the instance functions identically when created from this existing stock image as when created from “scratch”, with a Vanilla AMI configured by Puppet.
Setting up auto scaling is a complex and time-consuming project for any engineering team. No doubt over the next few years, third party tools will emerge to facilitate this process, but these cloud management tools have historically lagged far behind cloud adoption. Until tools like Amazon’s OpsWorks become more robust, the effectiveness of any environment’s auto scaling process will depend on the skills of cloud automation engineers.
Logicworks is a cloud consulting partner that helps clients achieve 100% availability on AWS. Contact our DevOps engineers to learn how to correctly implement auto scaling.

5 Comments